现在 ai 做 web 太简单了 甚至比做 cli 都轻松 很多大厂出了 build(比如 google aistudio build,vercel build,腾讯的元器等) 让小白也能按照自己的想法随便做成自己想要的网页出来
flutter/dart 一次编写全平台都能发布(
gpt pro 订阅重度使用 codex 模型为 gpt5.5xhigh 一天大概 200 多刀 3 亿多 token 消耗 缓存命中得占了 95% 以上
连搜都不想搜那没辙 sharex 官方自己都出了跨平台的重构版本 https://github.com/ShareX/XerahS
要 OCR 识别+二维码识别+GIF 录制截图等一堆功能的话 为什么不试试开源的 ShareX 跑过去玩人家收费的软件干嘛? 这软件还能能在截图后进行一系列的自动化操作 上传图床 图像处理 自动识别啥的
@february2 额 敢问阁下的系统 屏幕分辨率 对应的桌面缩放比例 浏览器缩放比例分别是多少( 在我印象里应该不会这么小的
我自己的屏幕分辨率是 windows 端 4k 200% 桌面缩放 浏览器 100% 缩放没这么小来着
boss 血条下次调整一下放到底下图层去让其不再影响鼠标
另外其实我不修改程序也有解法 1.倍速功能 点击左上角的目标即可快进到 boss 战 但是这是作弊功能 会影响成就的获取 不影响金色卵鞘的获取 2.按 F 键有自瞄功能,就不用鼠标瞄准了
asr 应该不免费吧 我感觉视频提取音频 asr 文本转录->大模型翻译->然后中文 tts 洗稿输出应该很有搞头 还有 tts 模型限时免费也不知道免费到什么时候
拿到了一个月的 pro 订阅 😙 正好能拿来测试 mimo 的 tts 和 asr 服务,接到我的配音工具上来用
我也没说不是 ai 写的啊 开头第一句话就点名了用的工具了 😇
说的是主角还是敌人
主角的速度我砍过一次了(
敌人的得困难后期速度才快(
调整了下 新增障碍物和水坑 障碍物用红色虚线表示 水坑用蓝色虚线表示
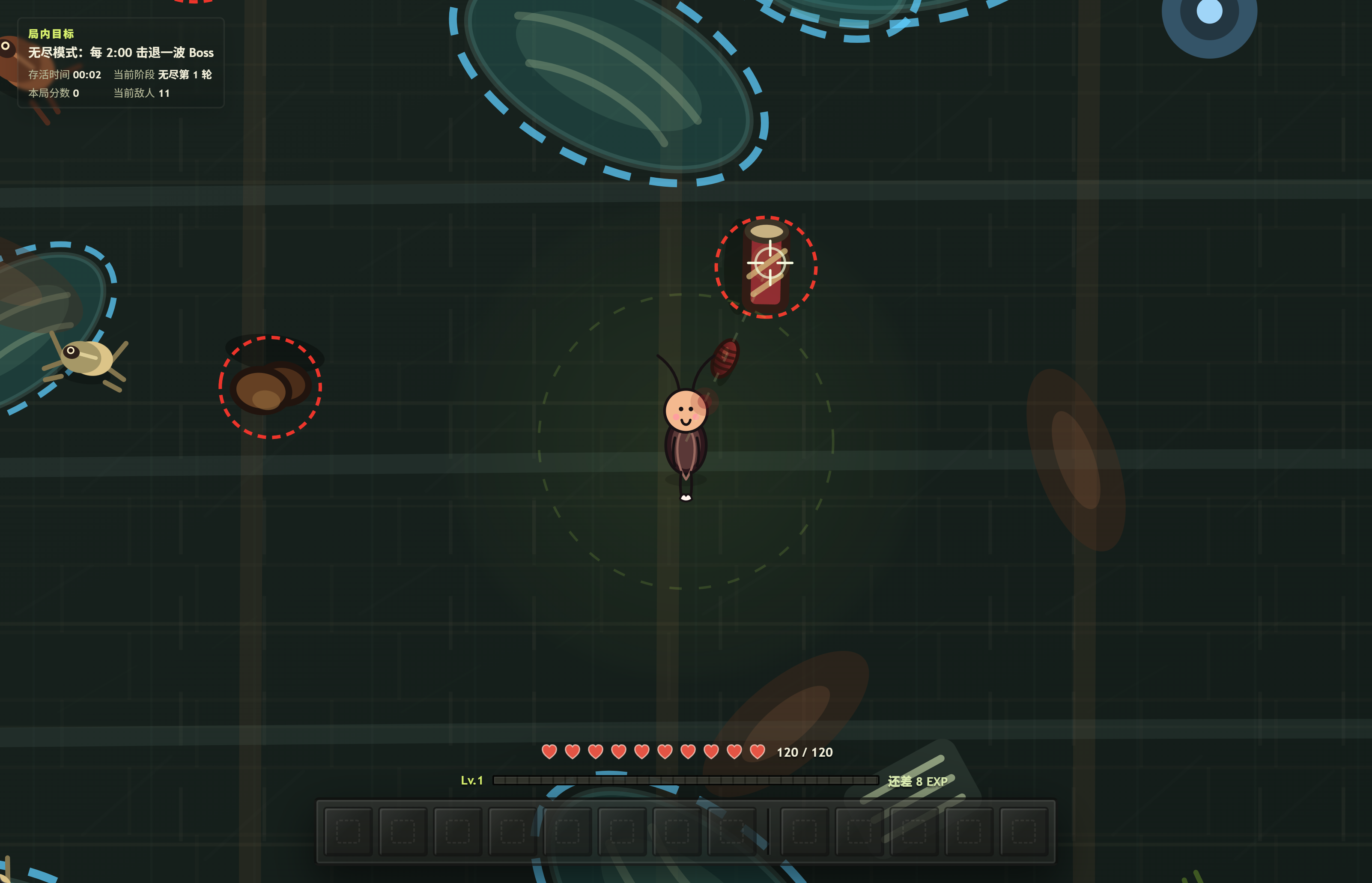
局内信息调整了下 改成半透明毛玻璃样式
困难第二阶段的 boss 是我故意调整的,就是为了整人,不点速度升级必定会被追上,想不被追上也行 找个障碍物和他玩秦王绕柱(
无尽模式也已经添加了,提醒一下无尽模式后面会很卡(
技能图表也改了下 css 样式 现在应该没这个问题了
改了 子弹做成黑红色的那种 更像蟑螂卵鞘了( 战斗的背景也稍微修改了下
更新了下 这次把地图上的障碍物都加了红色虚线显示 这次应该不至于看不清墙了 🤓
硬件也分的啊 有专门画 pcb 板的 有的专门焊板子测试板子的 有的专门给板子写各种软件比如计时检测啥的 不知道你做的啥 而且很多硬件用的技术都是完全不同的不像 python java 那样通用 想找个专门的硬件论坛还是挺难的
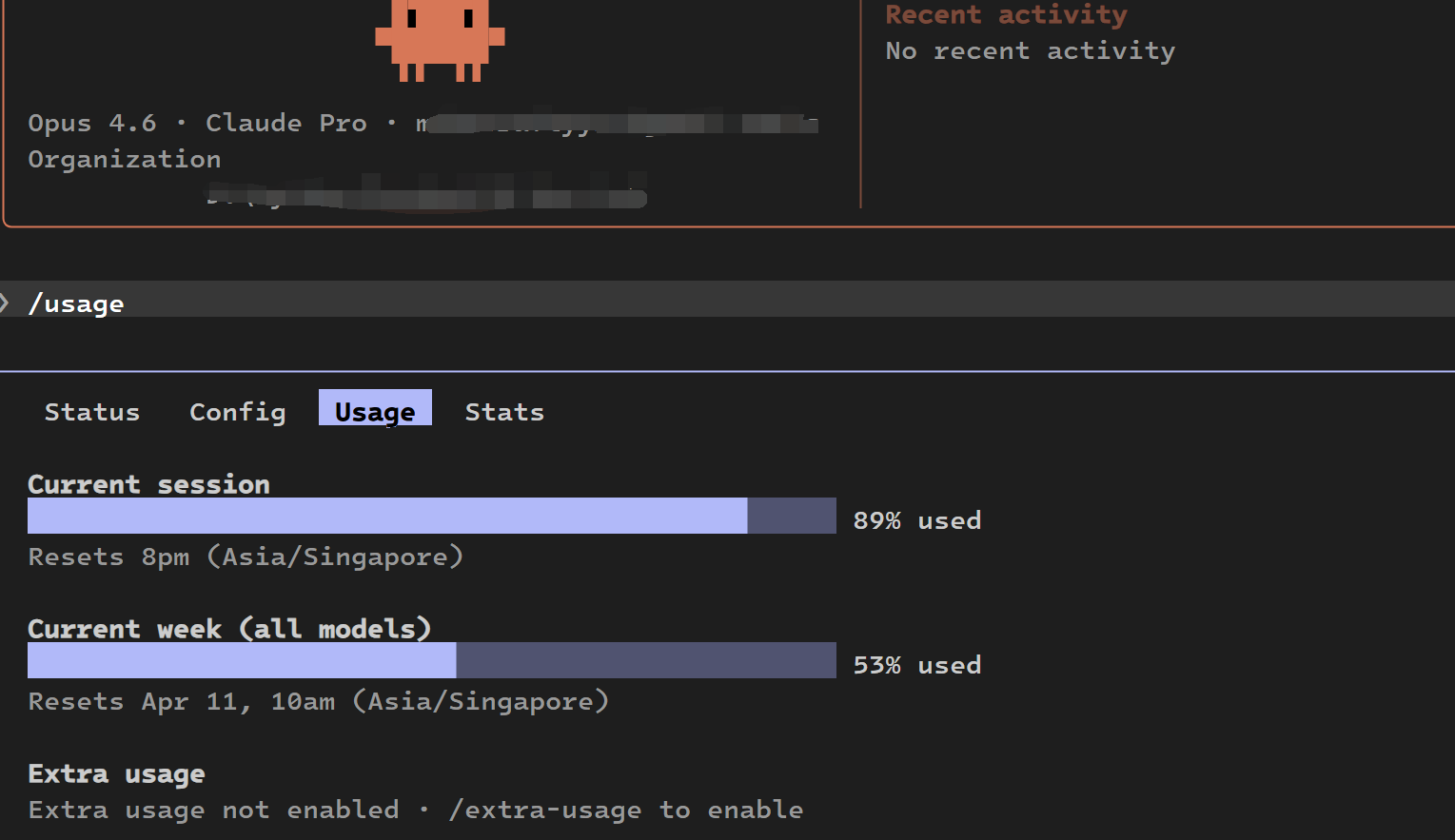
claude pro 的额度才是真不够用,想爽用得上 max x5 了 😂
如果你是写 python 的,为什么不试试 fastapi?fastapi 自带 Swagger UI ,开完程序后就能进网页动态调试 api
拿 google play 绑国内信用卡 然后在 app 里面内购使用 claude 都能以这种路子充值
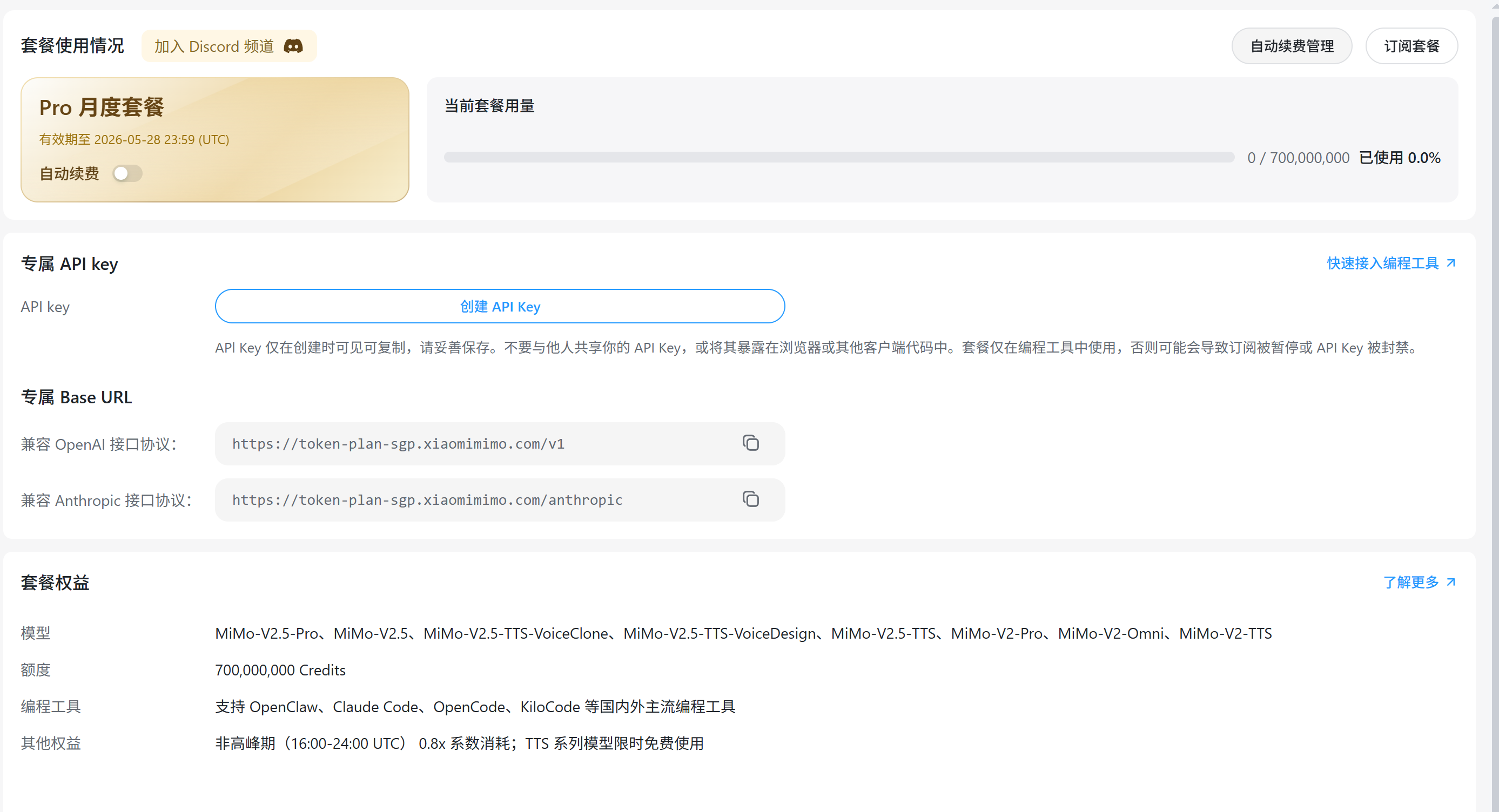
还真是免费的 我还以为必须充 plan 才能用 刚才没充余额直接去控制台弄了个 apikey 就能用
但是这玩意不支持语音克隆就很蛋疼(
在 openrouter 上面 pro 是输入 1 刀/m 输出 3 刀/m 的价格
按 lite plan 来算应该不算亏 但是如果丢给 openclaw 这种的怕不是立马就能吃完(
话说有大佬评测过他的 tts 模型吗 比较馋这个
确实是正版异步联机起来才有意思 一代最记忆犹新的是那个打大型 BT 会有小黑人送装备 感动哭了 😭 等明天就能体验到了 破解先暂时不管他了
草 怎么成信息流了 向手机端看齐了是吧
方便面吧 经常有人分享零食啥的 挺不错的
还好吧 纯送快递模拟器 玩一代的时候也没啥吓人场景的
上一代 pc 版是 505games 发行商 才送的 这一代是索尼发行商 按照索尼尿性应该不会让他上 epic 随便送 😵
灌注嘉然喵 灌注嘉然谢谢喵
终于支持竖排标签页了 😭
两三个月前就看到有新闻说这玩意在 chrome 金丝雀版本里面内测了 那时我在想啥时候上正式版,现在终于有了
但是真的值得更新吗 听说新版 chrome 里面会内置塞一个大小 4gb 的 ai 模型
苹果强不等于 arm 强 其他用 arm 的芯片真就一地鸡毛 编译个软路由系统还要设备树 人家做 nas 系统的飞牛 os 为了支持不同硬件需要编译 n 个版本这谁顶得住,
还有苹果即将不支持 intel 芯片的 mac 系统了,上一代 intel 芯片的 mac 才发布不过 7 年
想来想去,还是 AMD64 架构兼容性够好,够强,未来十几年至少在专业/游戏领域都是 AMD64 架构的天下
世道已经变成这样了吗 😭
还真是 现在 vibe coding 我就纯提需求和看需求有没有实现了 我成甲方了 ai 成了那个苦逼的程序员了 🤪
Martix 吧 不过大陆境内应该没人敢架设 Martix 服务器(
@mambaout uv 对 conda 的支持不太行 如果做一些大型开发的话还是上 pixi 吧
日常使用倒是无所谓了,我直接一个 anaconda base 打天下(
下面是 ai 回答的表格,可以参考一下

支持 conda 多语言支持 一个项目里面能塞下 python rust nodejs 等语言进行同时管理
pixi 自带集成 uv 计算环境依赖版本够快
把 pixi 当成 uv 的超集就行
iwara.tv
看不可描述的二次元小视频的网站(
不支持 B 站。B 站有专业的类库(比如 lux 或者 BBDown)可以处理,我这个项目是纯针对 I 站开发的,专门处理 I 站的接口加密和画质回退。建议术业有专攻,下 B 站用专门的工具更稳。
不使用嗅探技术。嗅探逻辑是基于浏览器捕获,你得自己一个个点开网页去抓,效率太低。
我这个是直接对接 API 的爬虫逻辑,你把作者主页链接一贴,它会自动分页把该作者名下的几百个视频全部抓取并排队下载,支持一键批量操作,这才是工具存在的意义
v 站有 需要使用青龙脚本 搭配环境变量设置 cookie 用
import requests import time import json import os import random import re # -------------------------- 尝试导入通知模块 -------------------------- try: from notify import send except ImportError: def send(title, content): print(f"\n[通知] {title}\n{content}") print("\n 未找到 notify.py 模块,取消推送") # -------------------------- 核心逻辑 -------------------------- class V2exSigner: def __init__(self, cookie, index): self.cookie = cookie self.index = index self.headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36", "Referer": "https://www.v2ex.com/", "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8", "Cookie": self.cookie } self.session = requests.Session() self.session.headers.update(self.headers) def sign(self): print(f"\n==== 账号 {self.index} 开始签到 ====") try: # 1. 访问签到页面获取 once 参数 res = self.session.get("https://www.v2ex.com/mission/daily", timeout=20) if "登出" not in res.text: return {"status": "失败", "msg": f"账号 {self.index}: Cookie 已失效或未登录"} if "每日登录奖励已领取" in res.text: return {"status": "成功", "msg": f"账号 {self.index}: 今日已签过"} # 正则匹配签到链接 pattern = r"location\.href = \'(.*?once=.*?)\';" urls = re.findall(pattern, res.text) if not urls: return {"status": "失败", "msg": f"账号 {self.index}: 未找到签到链接,可能已签到或页面结构变化"} # 2. 执行签到请求 sign_url = "https://www.v2ex.com" + urls[0] self.session.headers.update({"Referer": "https://www.v2ex.com/mission/daily"}) self.session.get(sign_url, timeout=20) # 3. 验证签到结果 res = self.session.get("https://www.v2ex.com/mission/daily", timeout=20) if "每日登录奖励已领取" in res.text: # 获取余额和奖励信息 balance_res = self.session.get("https://www.v2ex.com/balance", timeout=20) # 尝试获取今日金币 reward = re.findall(r'<td class="d"><span class="gray">(.*?)</span></td>', balance_res.text) reward_info = reward[0] if reward else "成功获取" # 获取总余额 total = re.findall(r'<td class="d" style="text-align: right;">(\d+\.\d+)</td>', balance_res.text) total_info = total[0] if total else "未知" return { "status": "成功", "msg": f"账号 {self.index}: 签到成功!奖励: {reward_info},余额: {total_info}" } else: return {"status": "失败", "msg": f"账号 {self.index}: 签到请求已发,但页面仍显示未领取"} except Exception as e: return {"status": "异常", "msg": f"账号 {self.index}: 异常 -> {str(e)}"} def main(): # 环境变量:V2EX_COOKIE cookie_env = os.getenv("V2EX_COOKIE") if not cookie_env: print(" 未找到环境变量 V2EX_COOKIE,请在青龙后台设置") return # 分割多个 Cookie cookies = re.split(r'[&\n]', cookie_env) cookies = [c.strip() for c in cookies if c.strip()] print(f"共发现 {len(cookies)} 个 V2EX 账号") # 随机签到模式 (保持一致风格) random_signin = os.getenv("RANDOM_SIGNIN", "false").lower() == "true" if random_signin: delay = random.randint(1, 1800) print(f"随机签到已启用,随机延迟时间窗口: 30 分钟") print(f"当前任务将延迟 {delay} 秒后执行...") time.sleep(delay) else: print("随机签到: 禁用") all_results = [] for i, ck in enumerate(cookies, 1): signer = V2exSigner(ck, i) res = signer.sign() print(res["msg"]) all_results.append(res["msg"]) # 统一通知 if all_results: notify_content = "\n".join(all_results) send("V2EX 签到通知", notify_content) if __name__ == "__main__": main()
linuxdo 我没账号就没有了

GitHub copilot 学生会员白嫖了两年多了( 挺爽的
我习惯使用 windows 的 win+tab 进行切换应用 感觉还行(
站长新年快乐,分母+1😘
还没拿到验证码 😭 现在就是想问一下老哥后面用的啥 zero-shot tts 模型 ,qwen3 tts,indextts2 还是 cosyvoice3
,有比较过目前的 tts 模型各有啥优劣吗
老哥如果有兴趣的,可以互相交流切磋一下,考虑用一下我的 cosyvoice3 windows 一键包,
目前针对大批量的小说文本阅读做了优化,还整了个 tts api 服务  ( https://github.com/Moeary/CosyVoiceDesktop )
( https://github.com/Moeary/CosyVoiceDesktop )
豆包是 Omni 模型吧 训练时同时训练文本内容+语音内容 之前做数字人都是要做个 ASR+LLM+TTS,这种的话对实时聊天来说延迟是绝对不可接受的,而这种 Omni 模型拿来做虚拟老婆/数字人就挺香的
Qwen 有开源过 Omni 类的模型 你可以看看这个 Qwen3 Omni 的技术报告 https://arxiv.org/abs/2509.17765
我是反着来 有 v2ex 和 2libra nodeseek 和 deepflood 的号 linuxdo 一直没弄 现在貌似都提高门槛要邀请码了 😭
我自己是代码编程使用 github 送的 copilot 会员 一个月 300 次 gemini3pro/gpt5.2/Claude 4.5 的请求额度 普通模型就无限用
其他的就使用 openrouter 的模型,好处是企业级别的渠道 非常稳定,代价就是贵,不过充值可以用支付宝 冲个 10 刀就可以每天免费调用用他里面的免费模型 1000 次,目前里面的主力付费模型我用的还是 grok 4.1 fast 好处是速度快,价格低 输出 0.5 刀/m token ,智商第二梯队 搜索能力第一梯队,没有审查 🤗
阿里云/腾讯云/京东云的新用户资格之前都被我吃掉了 😭 再去买就没新人福利了
虚拟组网的话其他人也要下软件 有点不太方便了 😂
wireguard 还能内网穿透吗 之前以为都是以为这软件只是一个机场的游戏加速服务来着 后面我看一下 😙
这个看起来不错啊 纯公益 🥰
好的非常感谢 后面会考虑一下 🤪