做了一个基于 CosyVoice2 0.5b 的 Windows 有声书生成器 使用 3s 音频即可复刻角色音色 有声书制作的不二法宝
前情提要:之前在玩声音模型的时候想着哪个模型效果好一点 自己之前尝试用过了 so-vits-svc3.0(唱歌音色转换) rvc(实时变声 音色转换) indextts(tts 模型) cosyvoice(tts 模型)
要说玩到最后还是 cosyvoice 稍微称心一点 他主要有三点好
- 它是 tts 模型不需要自己丢音频进去转换,丢文字进去就能生成音频,同时不像 gptsovits 那样生成音频还要找专门的模型,没找到就自己找音频数据集来训练 他这个只需要 3s 左右的参考音频就能复刻角色音色出来 很适合复刻那种冷门角色的音色
- 占用显存比 indextts2 要小跑的还快,我自己 4070m 本地跑的大概是 10s 能跑 10s 音频 indextts2 是 2 分钟跑 5s 音频(不排除是爆显存的影响)
- 配置起来相对简单 配 indextts2 需要使用 uv 而 uv 下载有的库经常出问题 对 windows 支持性不太好,得转 wsl2/linux 才能跑起来
然后我后面就想着既然他是可以支持零样本复制(不需要专门训练过的模型即可推理)的,那理论上来说改改就能变成一个有声小说/角色对话/角色独白的创作器,丢进去文本,设置好后就能一键跑通,今天可以让孙笑川念经,明天就可以让蔡徐坤鸡叫 后天就可以前一句胖虎:"小夫我要进来了",后一句小夫:"啊不要" 这样的多角色语言配置功能 😜
于是就做出来这么一个玩意 套了一层 PyQt5 Fluent-Widget 的皮
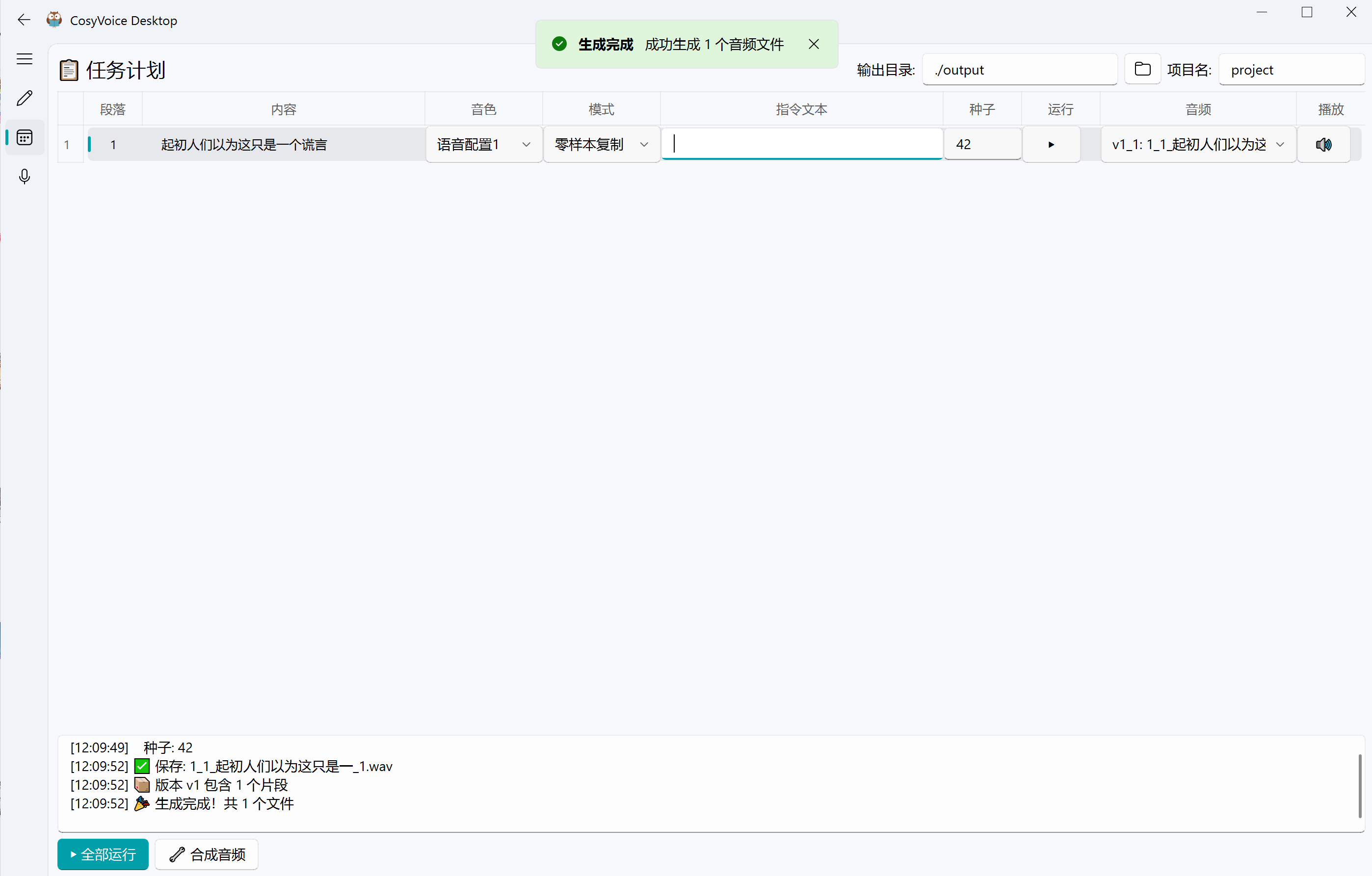
这个工具很适合有声书/角色独白/角色对话的制作,在语音音频配置界面设置好对应的参考语料后去主界面文本编辑部分打上对应颜色的标签,然后转成计划任务一键运行,然后遇到不满意的生成结果可以改变 seed 重新运行直到满意为止,最后点击合成能直接导出音频合集(对没错 就是这么简单就能创作有声作品)
然后放一个视频链接介绍先 CosyvoiceDesktop 一款面向创作者的多功能桌面端有声小说生产力工具 PS:这个视频配音的音频片段也是我拿这个软件生成的
这是仓库链接 CosyVoiceDesktop 我在这里不要脸的求各位大佬施舍一个 star 吧 😭
另外我做了一个一键包放到百度网盘里面了(链接在上面仓库的 readme 里面) 可以直接在 windows 上面运行(最好要有有 NVIDIA 显卡 但 50 系显卡因为 cuda 版本太高不支持,没有 NVIDIA 显卡用 cpu 也能跑就是慢了点而已),然后也可以尝试直接将那个 py 文件复制到 cosyvoice 仓库 的原目录里面跑,readme 里面都有教程跟着做就行了 😋
赞