正则表达式邪修,快速写出表达式
正则表达式有好多规则,组合起来可以实现特定的功能,自己写有些规则烧脑,现在有 ai 方便多了,但是保不齐有 ai 理解错了写出纰漏,如何在日常工作中利用正则表达式提高效率?
只需要会.+?x三个就够了,或者.+(?=x)其中x为终止符,比如:
要获取 2libra 首页的所有帖子链接和标题,爬虫的话可以根据网页结构爬,还是要先拆解结构,如果是临时获取,如何快速提取呢?

提取所有的/post/和标题
首先找到特征,所有带 post 帖子链接的情况有两种
href="/post/workplace-stories/uaTDQ7a">请问大佬们编程技术是如何进步的?纯帖子
href="/post/workplace-stories/uaTDQ7a?commentId=0738444d-60e0-4919-9233-15499970f60e&p=1">最后回复带回复的
我们只需要第一种,那就是以 post 开头,双引号结尾,且不带参数的,根据比对,第二种链接结尾有问号。
因为这里是邪修,所以不考虑提纯,先用正则表达式粗提取,再用 replace。
那么就是先用/post/.+?\"提取所有带 post 的链接。
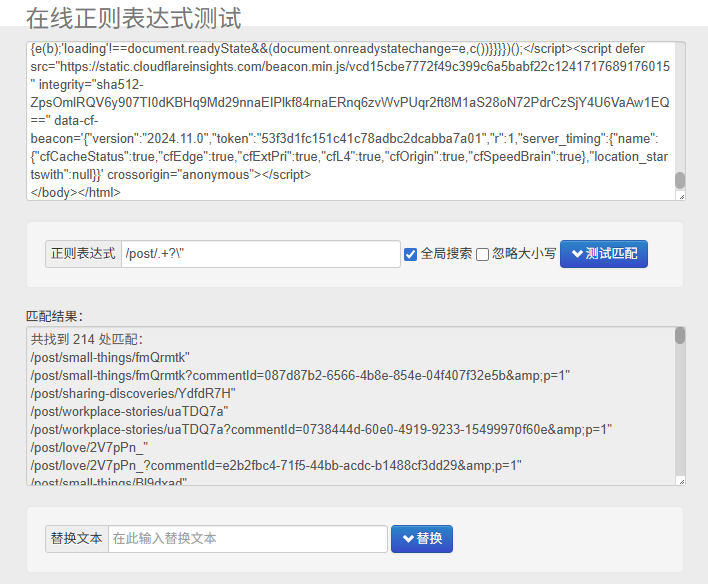
达到目的
本文是为了快速提取内容,所以这里没有用正则的限定长度,不追求一步到位,可以用限定长度取得更精准
然后去掉带问号的链接
然后如何获取标题呢?
一样的找规则,标题都是以>开头,以<结尾,但是这样会匹配到其他内容,所以可以把上面的复用。
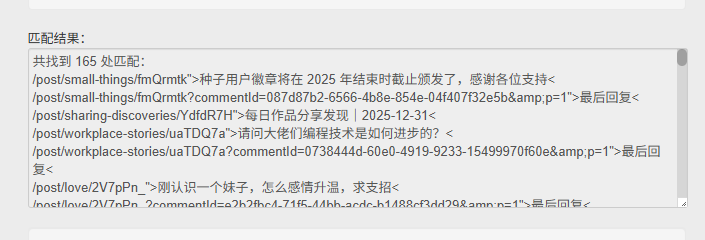
/post/.+?<这样就可以了
再用 split 和 replace 就可以了
可以看到后面的正则表达式一次可以完成两个内容的提取。
1、正则表达式粗提取
2、split、replace 提纯
再重复一遍,本文只是用于处理临时数据提取,将复杂问题转化为简单方法,把复杂的语法转为简单的 split、replace 这种简单的,可以用正则表达式做的更好,但是这里的目的是一秒想出表达式,适用于新手和简单场景,总结就是一句话,找到开始的特征和结束的特征,然后提取整段,去掉头尾得到内容。

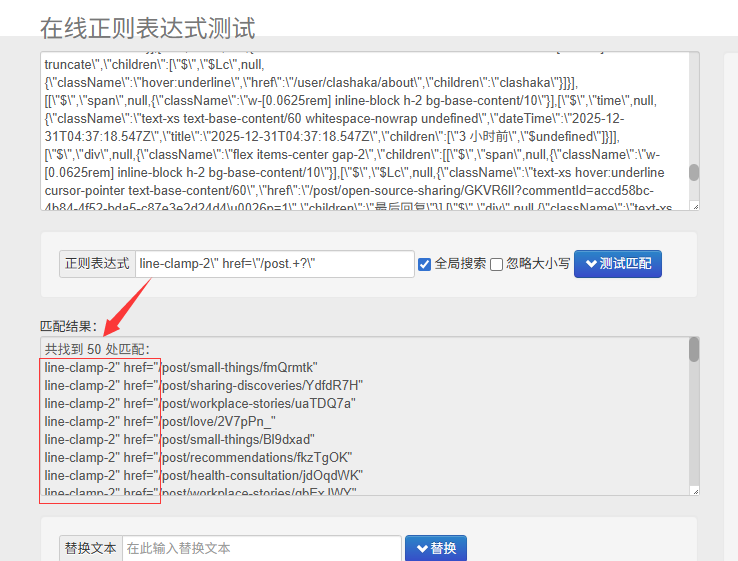
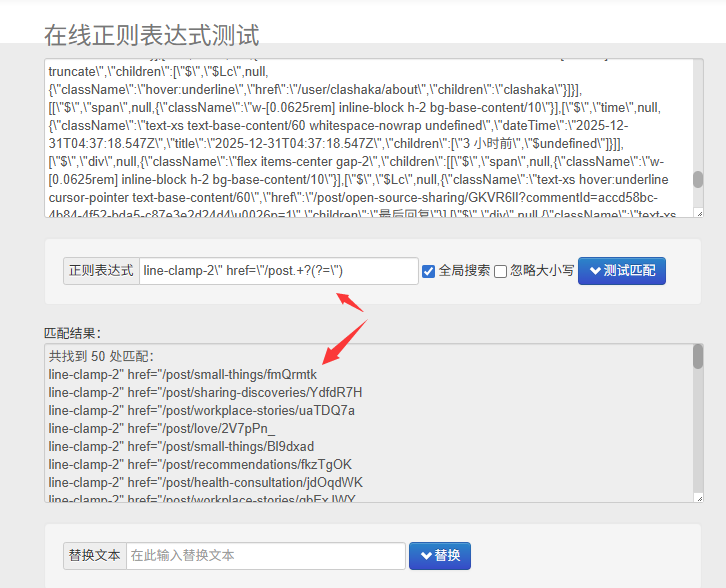
现在这种我都把需求提给 AI,让它帮我写了,包括但不限于正则、SQL、JS 脚本这类