做了一个 AI 生图提示词可视化工具:Candy Craft
平时写生图 prompt 的时候,我经常有一个感觉:
脑子里明明已经有画面了,但真写出来以后,模型不一定按这个意思生成。
有时候主体位置不对,有时候镜头感不对,有时候明明想做夜景,最后出来的布光却像白天。
我没怎么找到顺手的同类工具,于是自己搓了一个,名字叫 Candy Craft。
如果你也有下面这些情况,那它可能会有点用呀:
- 经常写生图 prompt,但总觉得结果“差一点”
- 写过很多提示词,但难复用、难回放、难微调
- 想把“脑子里的模糊画面”变成“几个可控参数”
一句话来概括:
它会先把你的一句话提示词拆开,变成可编辑的画面元素、构图、相机、布光和维度参数;
你改完之后,它再帮你整理成更适合生图模型理解的英文 prompt。
它不是“再来一个聊天框”,而是把提示词这件事,尽量做成一个看得见、改得动、能回放的流程。
项目页面: 点击即可跳转
V1.1:
- 优化移动端体验
- 细化“相机与布光”模块,三视图联动,优化光源显示方式,增加单独运算光线轮次
- 构图方向目前可自动识别
- 增加画板视图聚焦以及任意缩放物体大小功能
V1.0
先看效果
完整演示 GIF:

效果图:
AI 最优选:

非 AI 最优选,为 GIF 里我手动修改后的结果:

它大概是怎么工作的
你先把一段原始提示词交给助手,助手不会直接帮你“润色一句话”,而是先把这段提示词拆开来看。
它会先分析出这段提示词里比较关键的几个部分,比如:
- 画面里有什么主体
- 主体和背景大概怎么站位
- 整体更偏什么风格
- 适合什么镜头语言
- 更适合什么光线和氛围
- 哪些地方细节要强,哪些地方可以收一点
分析完之后,这些内容不会只藏在一大段说明文字里,而是会变成你能直接调的东西:
- 几个维度滑杆
- 一个可拖拽的画板
- 一个相机与布光面板
- 一些可选的预设建议
你可以把它理解成:
- 原始提示词,是你随口说的一句话
- 分析阶段,是助手先把你真正想要的画面拆出来
- 可视化编辑阶段,是你和助手一起摆人物、摆机位、调灯光
- 最后优化输出,才是把这些内容重新整理成模型更容易理解的 prompt
所以它做的不是“帮你换一批更花哨的词”,而是把提示词从一段模糊描述,变成一个更结构化、更可控的东西。
核心能力
1. 雷达图:先把“你到底想要什么感觉”看清楚
很多人写 prompt 的时候,其实说不清自己这段描述更偏什么:
- 更重细节
- 更重氛围
- 更重光影
- 更重叙事
- 更重材质
写的时候感觉都想要,最后反而容易混在一起,结果就是模型收到一堆“都想要”的要求,生成出来不够稳定。
Candy Craft 会先把提示词拆成几个核心维度,比如画面细节、光影层次、色调氛围、构图张力、材质表现、叙事深度,然后把它们画成一个雷达图。
这样你一眼就能看出来,这段提示词目前更像什么:
- 是偏氛围、偏电影感
- 还是偏细节、偏写实质感
- 还是偏构图冲击力、偏海报感
它不是替你做决定,而是把原本很抽象的“感觉”,变成一个能看、能比较、能微调的东西。

2. 画板:把“提示词里的画面内容”变成一个能摆位置的草图
很多人写 prompt 时,脑子里其实已经有画面了,比如谁在前面、谁在后面、主体偏左还是偏右、背景大概占多大、焦点落在哪。
但这些东西如果只靠一句文字去描述,往往不够稳定。
所以画板的作用,就是先把这些内容拆出来,然后让你直接在界面里摆:
- 谁在前景
- 谁在后景
- 谁更大、谁更小
- 谁更突出、谁只是陪衬
- 焦点应该落在哪个元素上
简单说,它是在帮你控制提示词里最容易失真的那一部分,也就是“画面怎么摆”。
任意添加/修改人物信息、调整位置与大小:


链接功能,可以更细地设置人物关系,也支持自定义关系:

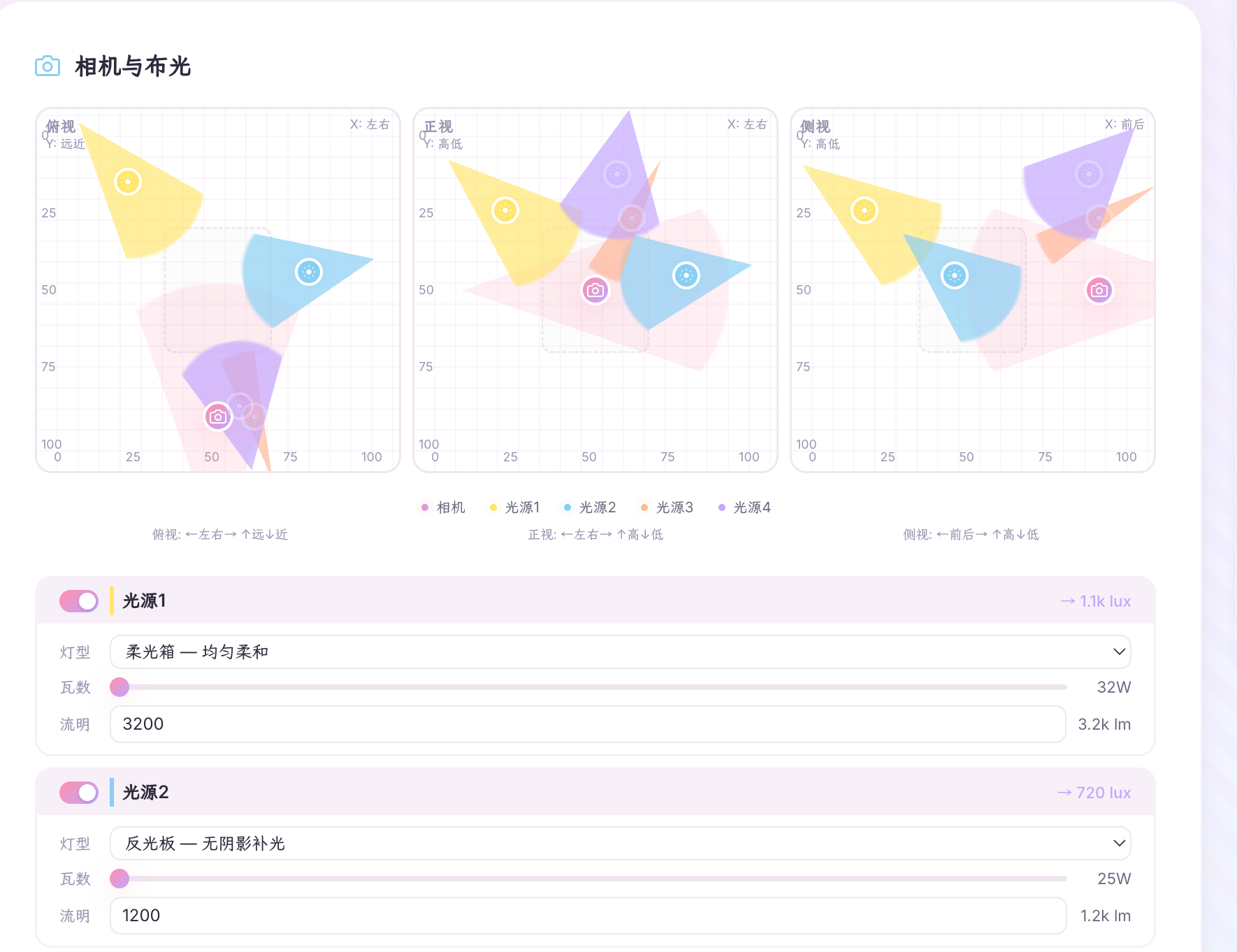
3. 相机与布光:不只告诉模型“写什么”,还补上“怎么拍”
很多人写 prompt 的时候,只会写主体和场景,比如:
“一个女孩站在夜晚街头,霓虹灯,电影感。”
但对生图模型来说,这种描述还少了一层很关键的信息:
- 机位是平视、俯拍还是仰拍
- 画面是近景、中景还是广角
- 光从哪边来
- 整体偏冷、偏暖,还是强反差
这些如果不说清楚,最后就很容易出现“意思差不多,但味道不对”的情况。
所以我做了一个相机与布光面板,你可以把它理解成一个简化版的小摄影棚:
三视图功能,更直观,也更容易上手:

机位、灯光流明、色温、时段都可以调:

你拖动相机或者灯光点位的时候,工具不会把一堆坐标硬塞给模型,而是会把这些信息整理成更适合 prompt 的语言,比如低角度、侧光、逆光、柔光、冷色氛围之类。
所以这块的核心作用,不是让你真的去做专业影视布光,而是用更直观的方式,把“镜头感”和“光线感”补进提示词里。
这样生成出来的东西,会比单纯写一句“电影感、氛围感、大片感”更稳定,也更接近你真正想要的画面。
当你改了场景或提示词重新分析后,AI 会重新计算新的建议,并询问是否覆盖当前设置:

4. 双 API 模式:开箱即用,或者自己接上游都可以
目前接口格式走的是 OpenAI 兼容路线,一共两种模式:
- 后台托管:开箱即用,适合先体验;不过大家一起用的时候速度可能会慢一点,还请见谅
- 用户自定义:可以填写自己的
Base URL / API Key / Model,浏览器直接请求你自己的上游,不经过本站后台。

5. 按照动漫——真实分为 10 档。以下是预览效果图,从上到下按 1~10 排列:










目前支持和定位
现在更偏向一个“提示词可视化整理器 / 优化器”,目标不是完全替你思考,而是把咱们本来脑子里那幅图,尽量更完整地表达给模型。
比较适合:
- 想把灵感快速落成 prompt 的人
- 已经会写 prompt,但想提高可控性的人
- 想做提示词回放、复用、微调的人
目前输出比较适合拿去喂:
- Midjourney
- Stable Diffusion
- FLUX
- Image2/其他 OpenAI 兼容流程里的文生图工作流
项目地址
如果佬们觉得这个方向有意思,或者觉得哪里做得蠢、哪里还能继续打磨,欢迎直接提建议呀!毕竟是昨天一下午做出来的,肯定会有问题的呜呜呜
AI 使用声明:本文章&项目部分由 ChatGPT/Claude 编写

有点意思,点个赞。还可以再接入一些生图的 prompt 库,一站式全搞定~