TTS 更新太太太太正啦, 多端通用 TTS 软件这条路到底该怎么走?
最近不知道各位有没有刷到 VoxCPM2 TTS 模型 的新闻,这玩意实在是太强了,让我陷入了深深的焦虑
先谈焦虑缘由, 大概半年前,我开发过一款基于 CosyVoice 的 TTS 多角色配音软件 。一开始做的时候觉得思路还挺清晰,但越做到后面越觉得不对劲,也越来越意识到自己陷得有点深了。
中途我也尝试过换推理引擎,比如接入 ONNX,或者继续适配其他 TTS 大模型,但实际开发下来发现难度很大:
一方面,不同模型的接口、能力和 Python 环境依赖差异太大;
另一方面,很多模型本身就不是为了“统一接入、多端通用”这种场景设计的。
就在几天前填上了最后一块 API 更新的拼图后我就打算放弃更新这个桌面版本了,后面再怎么优化都有点像“屎上雕花”。
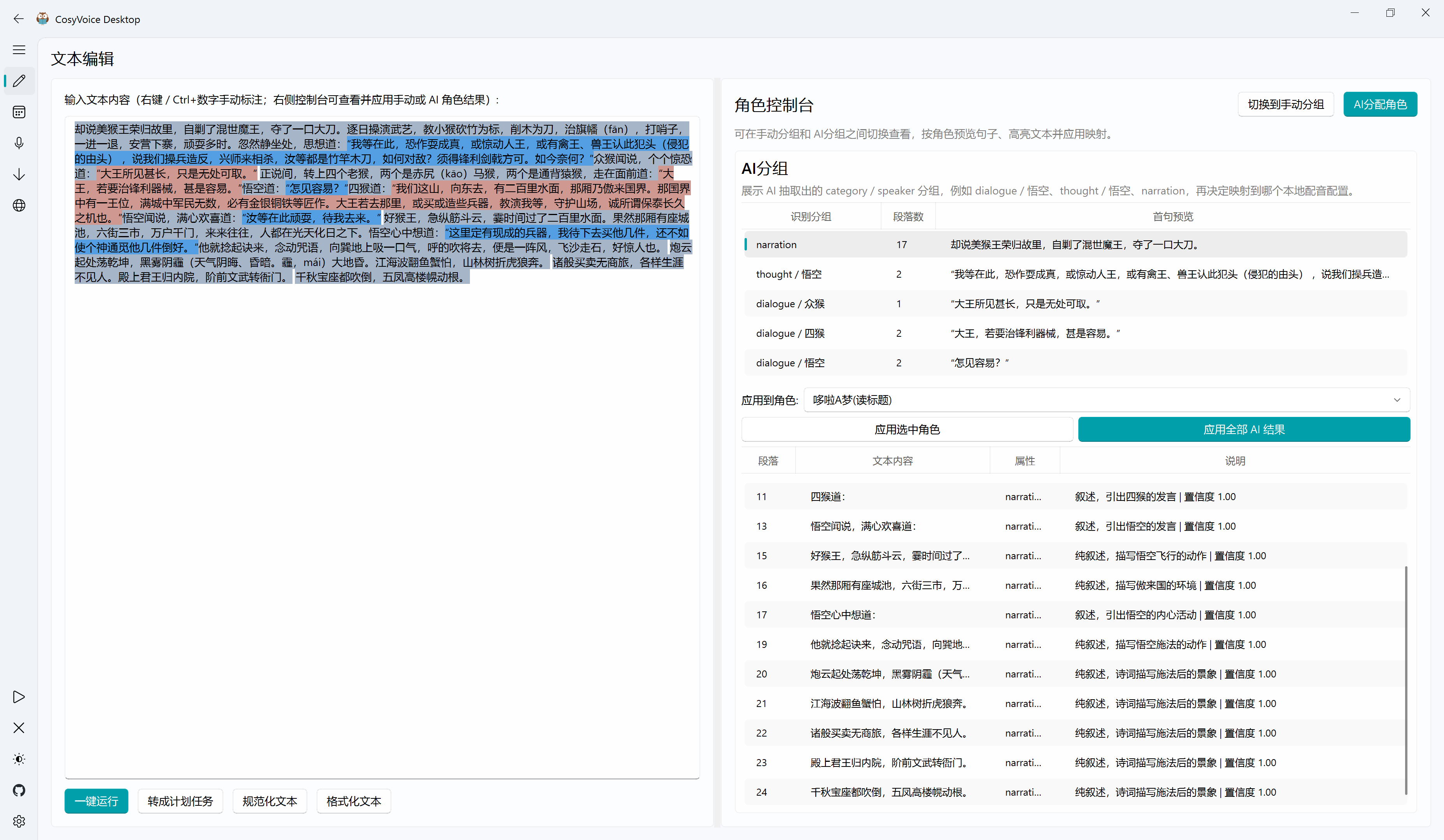
上次更的最后一版加上了让 LLM 自动分配角色(Json 格式化输出,不算太高深的技术)的功能,可以 AI 自动映射或者手动映射配音角色到待角色)
做到这里以后,我越来越觉得:
如果真的想做一个正常的、多端通用的 TTS 软件(哪怕是网页端也算),整体架构应该拆成这几层:
前端层:负责跨平台交互,比如 Flutter 或 Web。
中间适配层:负责统一不同 TTS 引擎的调用方式和能力描述。
后端层:可以接各种来源的 TTS 服务,例如:
- 云厂商提供的 TTS 服务
- 自建的大模型 TTS 服务(通过 HTTP 提供接口)
- 系统自带的 TTS 服务
现在市面上的 TTS 大模型实在太多了,同时更新的速度也太快,而且各家能力差别非常大:
有的支持语音克隆(Cosyvoice Qwen3 TTS IndexTTS VoxCPM 等) (尤其要针对语音克隆做适配,这玩意最适合多角色配音),有的支持指令控制,有的支持声音定制(Qwen3 TTS),还有的只能从训练好的角色里抽取说话人来跑推理(比如 GPT-SoVITS 这一类)。
如果从“用户体验”角度来看,未来肯定需要有一套标准化的适配方案,把这些能力尽可能统一起来,而不是每接一个模型就重写一套逻辑。
所以我现在有个新的想法:
想做一个以多端 TTS 软件为核心的开源组织 / 项目体系。
大致方向是:
主仓库做一个 Flutter 前端(或者其他跨端前端)
各种 TTS 引擎单独拆分成独立 repo / 插件(推理引擎最好是 vllm-omni>onnx>pytorch, 同时也要保持 TTS 单独的使用能力,对外使用 FastAPI 暴露 提供调用模型原生推理的接口 和提供 OpenAI TTS API 兼容的接口,确保能被其他软件使用)
用户只需要下载一个统一前端,然后可以自由选择接入自己想要的后端, 尽量以统一的方式体验最新的 TTS 模型
现在已经做了一个基础的 flutter demo 了,能接入 OpenAI TTS 接口兼容/OpenAI ChatAPI 接口兼容/Cosyvoice 的推理接口 (其他的还没实现,因为暂时缺乏统一标准 我只能做我手上有的,Cosyvoice 那个推理接口还是我自己改我之前软件实现的)
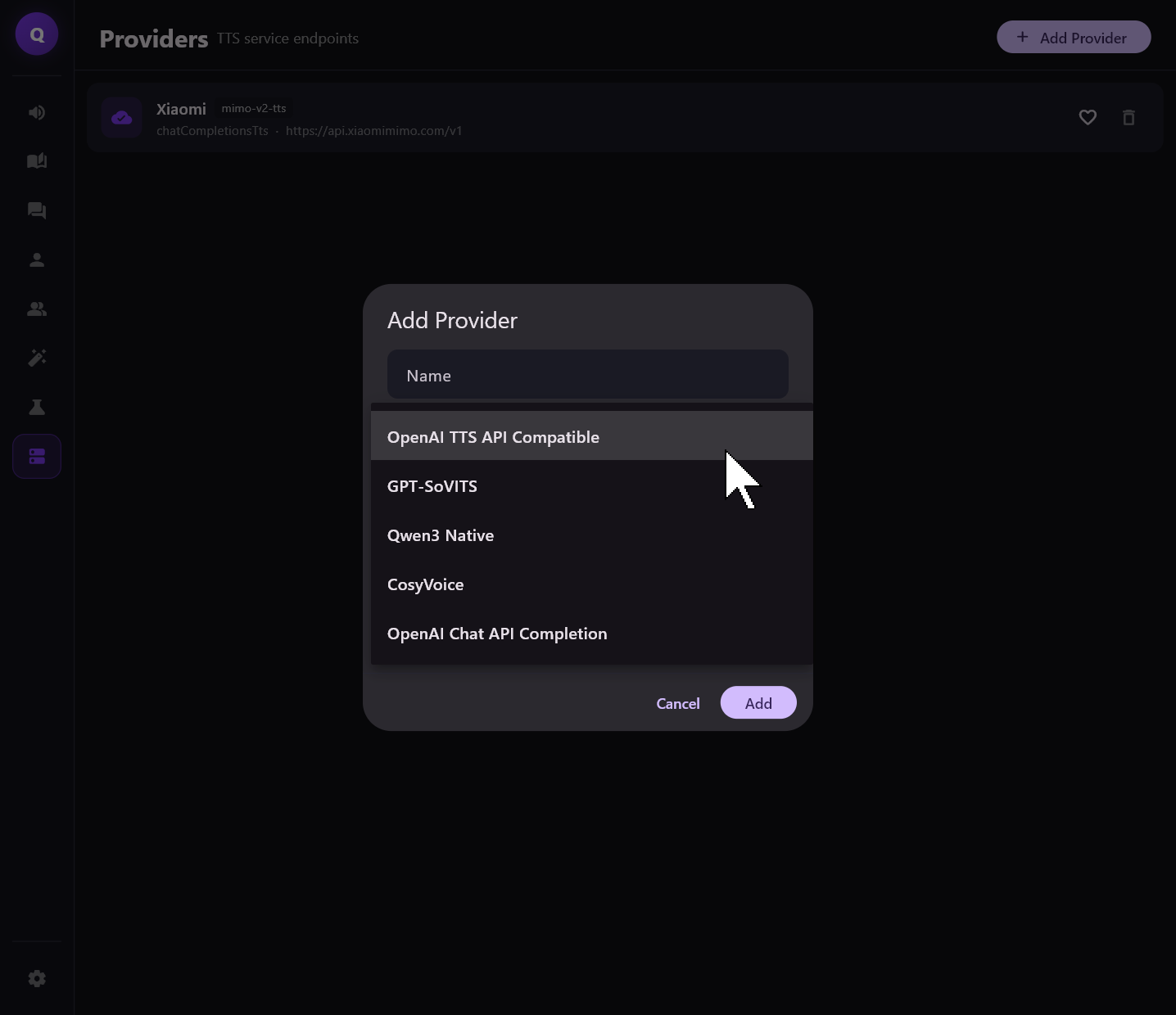
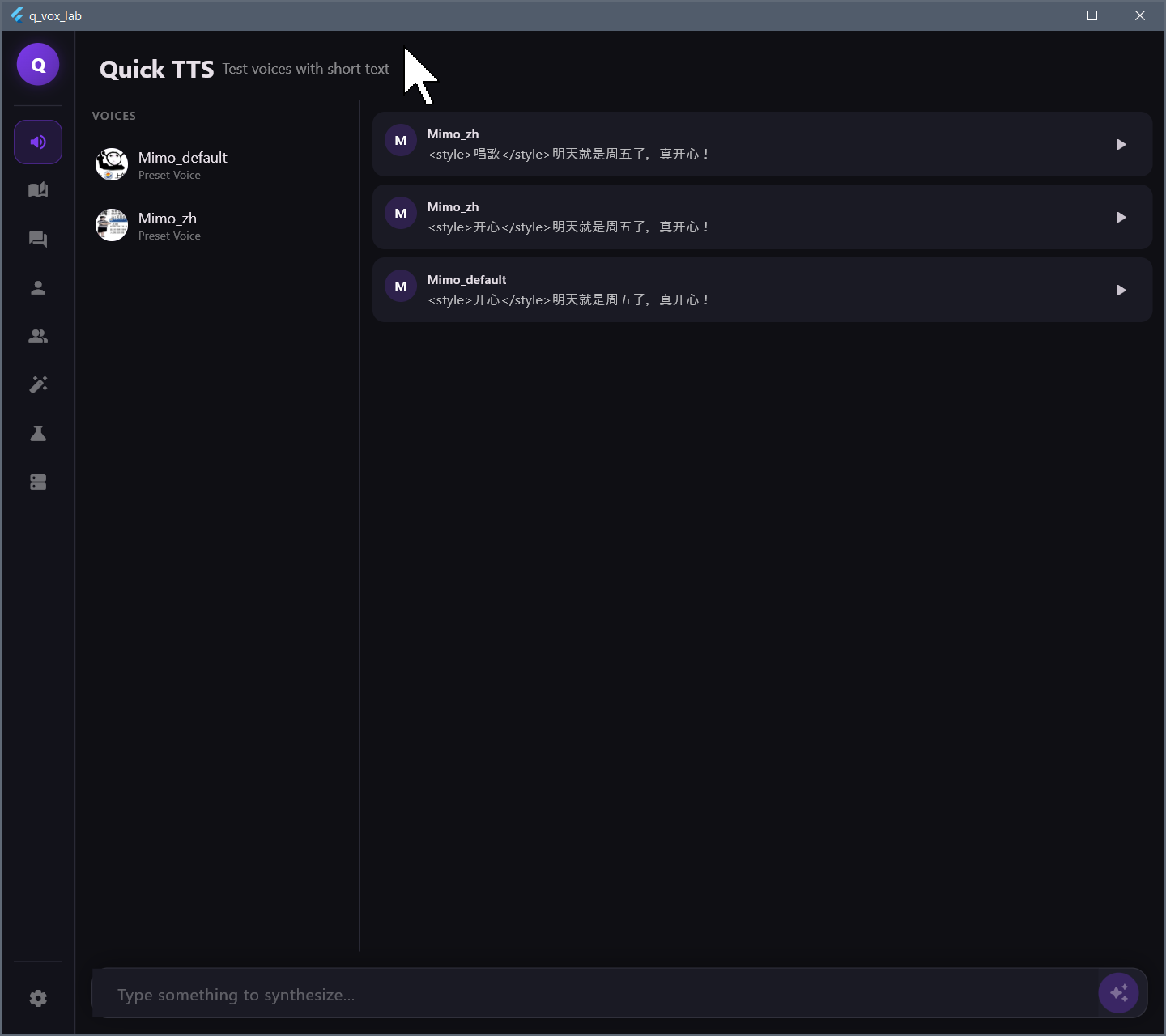
不知道做个这玩意是否有前途,希望有大佬指点指点